During the project
This illustration is created by Scriberia with The Turing Way community.
Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
TU Delft ICT Network drives
These are accessible from the TU Delft network (e.g. via Windows File Explorer)
| Personal Drive (H:) |
8 GB |
Just you |
Yes (but not research data) |
| Staff Group Data (M:) |
50 GB |
Department |
No |
| Project Data (U:) |
5+ TB |
Managed by drive owner (project PI) |
Yes |
Need more computing power?
Cloud drives
| SURFDrive |
1 TB |
Just you (can share files/folders) |
Yes |
| Microsoft OneDrive |
1 TB |
Just you (can share files/folders) |
Yes |
Pros-cons
TU Delft ICT Network drives
-
✔️ Regular backups (3-2-1 rule)
-
✔️ Secure storage
-
✔️ High volume storage (5TB+)
-
❌ Needs internet connection (and EduVPN)
-
❌ Can’t share single files/folders (all or nothing)
Cloud drives
-
✔️ Synchronisation with local device
-
✔️ Version controlled
-
✔️ Advanced sharing
-
❌ Not secure, not appropriate for sensitive/personal data
-
❌ Not compliant with 3-2-1 backup
-
❌ Account deleted shortly after researcher leaves
Backups
3-2-1 backup rule-of-thumb
3 copies of the data (1 primary, 2 backups)
2 different storage media (e.g. external hard drive and laptop)
1 copy stored offsite (different geographical location)
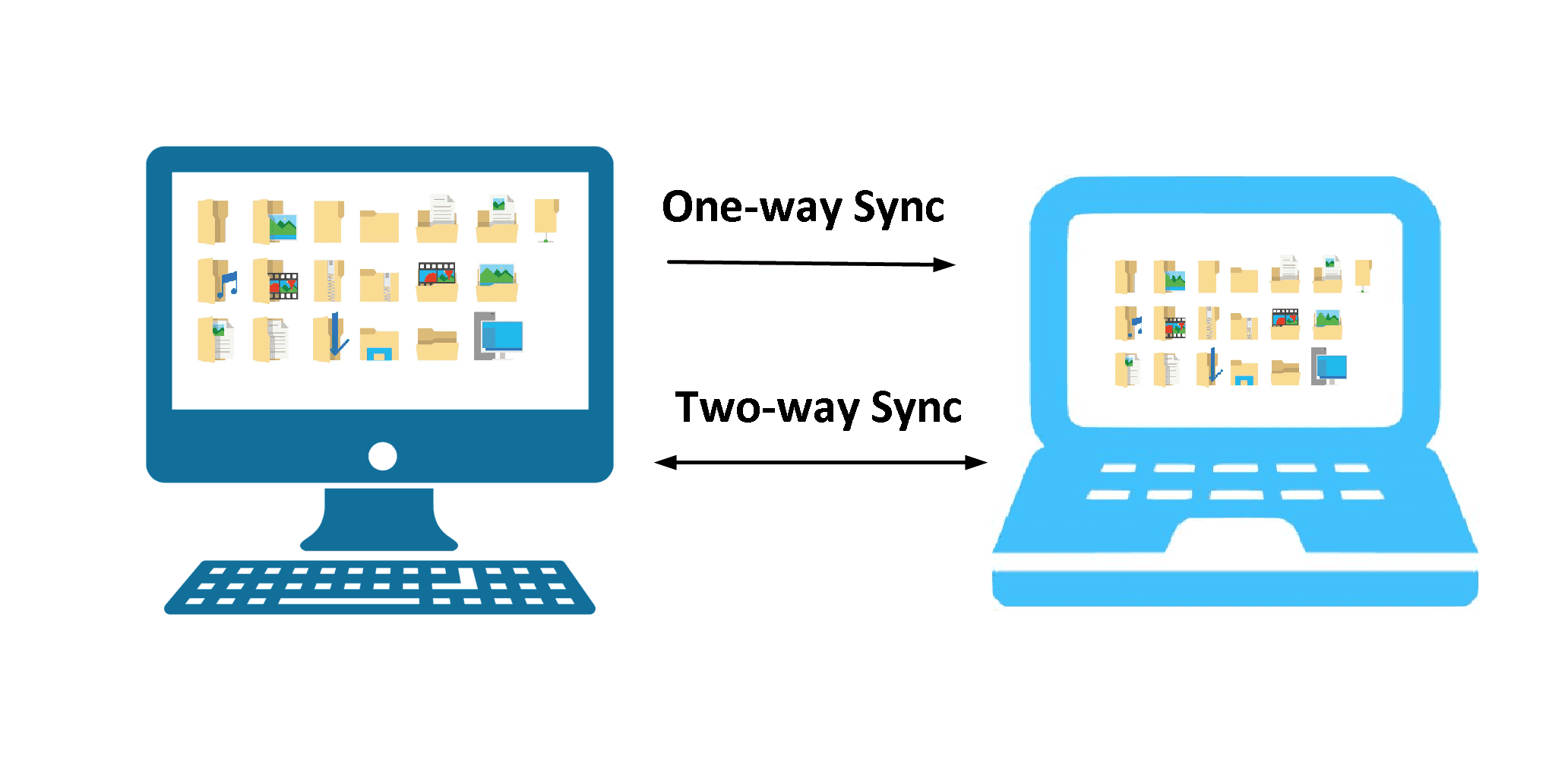
Backup types
Two-way (synchronisation)
One-way (backup)
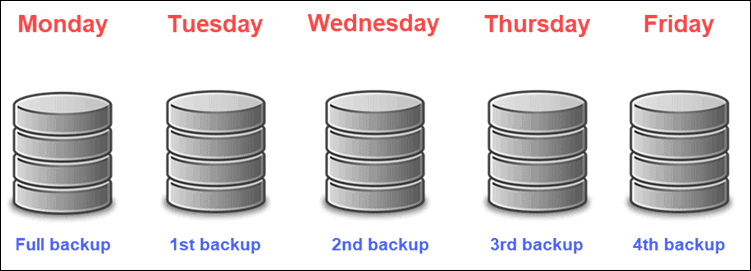
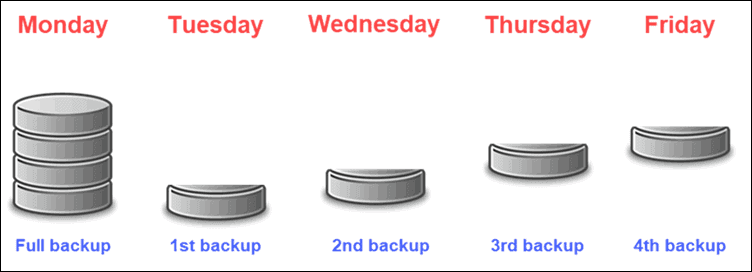
Backup types
Full backups
+ Easy to restore data
- Uses a lot of storage
Incremental backups
+ Uses less storage
- More complicated to restore data
Data sharing
SURFfilesender
- up to 1 TB
- End-to-end encryption up to 2 GB
Project/data organisation
Look familiar?
![]()
Can you walk away from your project for days, weeks, months,
and come back and know what everything is?
Spend some time thinking about how you will organise yourself.
Your future self will thank you…
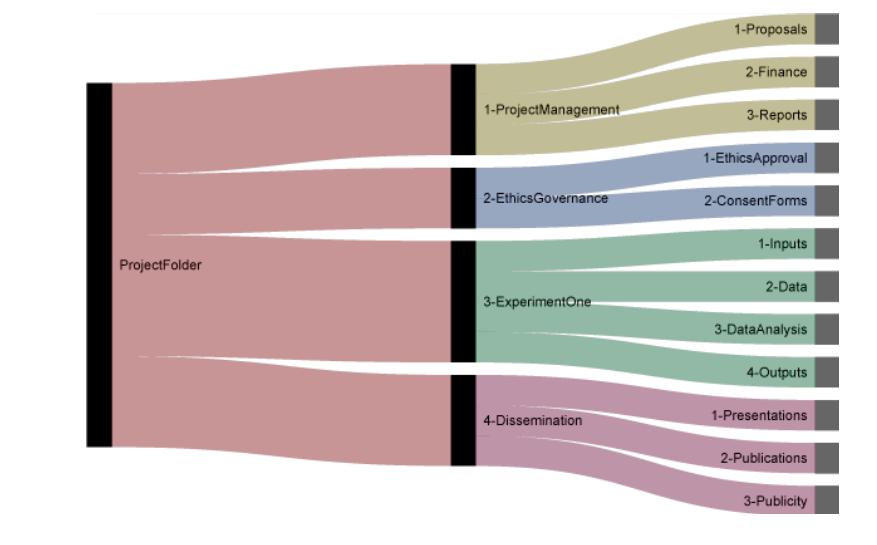
Project structure
Projects should be contained within folders in a meaningful place
📁 project_name
📄 README
📁data
📄 raw-data_exp01.csv
📄 raw-data_exp02.csv
📁analysis
📄 analysis-script.R
📁reports
📄 results-of-analysis.Rmd
📁publication
📄 manuscript_v1.docx
-
✔️ Could be in home directory (
~/Documents/Project_name)
-
✔️ Could be in the cloud (
OneDrive/Project_name)
-
❌ NOT on the Desktop
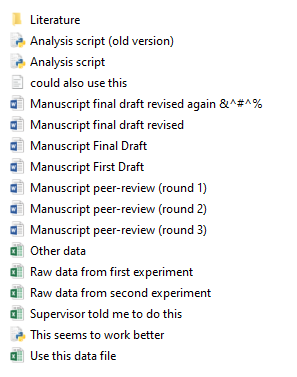
File naming
I know, I know, could there BE a more boring topic…
It is pretty essential, though. Follow these rules and it’ll be right 👍:
- Use dates where applicable: YYYY-MM-DD (ISO 8601 format)
- Use them at the beginning of the file name so it arranges by date
- Be descriptive, but brief
- Using a version number (not ‘final’ - there’s no such thing as a final version…)
- Avoid spaces and special characters (exceptions:
_ and -)
- separate related words with
- and chunks with _
- Avoid case-sensitivity (SomE operAting SystEms cARE, some don’t)
File naming continued
Good examples:
analysis01_descriptive-statistics.R
analysis02_preregistered-analysis.py
2009-01-01_original-analysis.R
Bad examples:
essay "romeo and juliet" draft01(1).docx
1-April-2012 supervisor comments on final draft.docx
From https://djnavarro.net/slides-project-structure/#1
Version control
By using a version control system (VCS - git is most widely used), you can:
- record changes to file(s) over time
- revert selected files back to a previous state
- revert the entire project back to a previous state
- compare changes over time
- see who last modified something, when, and more
![]()
This illustration is created by Scriberia with The Turing Way community.
Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
Version control hosting services
GitHub ![]()
- Popular host for developing open-source (and closed-source) projects
- share with nobody (Microsoft), collaborators, everybody
- Free account for individuals
GitLab ![]()
- Similar interface to GitHub
- TU Delft provides own server (secure for sensitive data)
- Share with nobody, collaborators, all TU Delft researchers, everybody
- Free account for individuals
VCS hosting services
They are NOT a certified repository for long-term storage
They do NOT assign DOIs
They CAN be connected with certified repositories
Snapshots of the repo will be taken and assigned a DOI
Documentation
What to document
- How to navigate the project
- How to (re-)use code and data
Ask yourself: can someone with access to your project folder, reproduce exactly your findings?
That someone may be your future self!
In practice
- Metadata embedded in files (instrument-specific)
- Paper or (preferably) electronic lab notebooks
- README file(s) in project folder
- Code annotation/software instructions
- Upload your data to repositories with discovery metadata
- Use disciplinary metadata standards (may or may not exist for your discipline)
Documentation: Lab notebooks
Conventionally kept in physical notebooks in lab or PIs office
This has some limitations
- does not relocate easily
- depends on handwriting legibility
- often not standardised
Documentation: Electronic lab notebooks
Several beneficial functionalities
- text editor
- spreadsheet tools
- protocol templates
- lab inventories
- sharing/collaboration options
- lab equipment/workflow managers
- integration with other resources (e.g. SURFDrive, OneDrive, and GitHub)
- version controlled
Spreadsheet organistion
Raw data… DO NOT TOUCH
Spreadsheet organistion
Raw data… DO NOT TOUCH
Make a copy of the raw data to perform calculations and analysis
- or, ideally, use a scripting language and export derived data
Spreadsheet organisation
One row per case
One column per variable
One cell per observation
Variable naming
-
✔️ use snake_case or camelCase
-
✔️ meaningful names (but short)
-
❌ No special characters or spaces
-
❌ start with letter (not number)
Code notebooks
If you just can’t choose!
![]()
![]()
![]()
![]()
![]()
See courses and workshops here
Summary
Project organisation - give it some thought
- documentation
- code notebooks
- lab notebooks
- version control
Data storage
- security
- backups
- metadata standards for your field
Working with personal data
Collect only what you need (and what you informed participants you would collect)
Access to personal data is restricted to only those who need to process them
Data should be stored in a secure location (e.g. Project Drive)
Informed consent forms should be securely stored
- paper forms: locked storage
- digital forms: encrypted and separated from the other personal data
Working with personal data
Anonymisation vs. pseudonymisation
Pseudonymisation: assign a unique participant number to each participant on the corresponding informed consent form or a separate key document. Use participant number (not their names), during data collection & analysis. This is not anonymization, since it is possible to trace each unique participant number to the corresponding participant.
- Key document needs to be stored in a separate and secure location (e.g. with the informed consent forms).
. . .
Anonymisation: Full anonymization is often difficult to achieve. It might be still possible to identify a specific individual by putting together indirect identifiers. Easier to achieve by data aggregation.
After the Project
This illustration is created by Scriberia with The Turing Way community.
Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
Archiving data/code
As a PhD student you are resposible for:
Ensuring that all data and code underlying completed PhD theses are appropriately documented and accessible for at least 10 years from the end of the research project, in accordance with the FAIR principles (Findable, Accessible, Interoperable and Reusable), unless there are valid reasons which make research data unsuitable for sharing.
- 3mE RDM Policy
Minimal requirement:
- deposition of processed data underlying figures and conclusions in published papers and dissertations.
Encouraged:
- deposition of raw data, software, data analysis scripts, protocols, etc.
Publishing data/code
Data are available upon request to corresponding author.
Publishing data
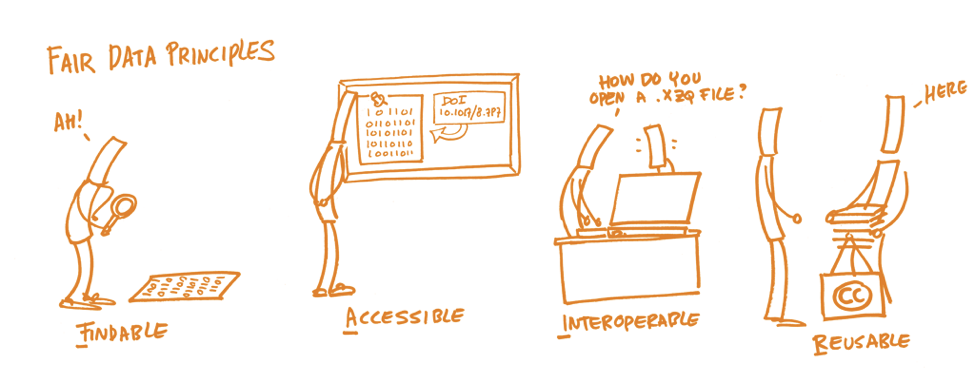
Be FAIR
![]()
Findable - persistent identifier (e.g. DOI) and detailed metadata
Accessible - long-term accessibility of data (or just metadata if restricted)
Interoperable - non-proprietary file formats
Reusable - proper documentation and clear license
Image: https://book.fosteropenscience.eu/
Publishing data
and CARE
![]()
Collective benefit - inclusive development and equitable outcomes
Authority to control - Rights, interests, and governance
Responsibility - respect, reciprocity, and trust
Ethics - minimising harm and maximising benefit
https://www.gida-global.org/care
Publishing data
As open as possible; as closed as necessary.
Are the data suitable for sharing?
- Personal data
- Commercially confidential data
- Data belonging to third parties
- Other types of confidential data
- Data too large to be published online in a repository
Publishing data
Licenses
![]()
Data ownership
As a general rule, TU Delft owns all research data generated by employees at TU Delft.
But funder of the project (either public or commercial) might impose ownership conditions.
Check whether existing relevant documents, such as grant/consortium agreement etc., specify:
- Who is allowed to use the data?
- Can the data be made publicly available?
- What is the publication procedure?
- The faculty contract managers can advise on these agreements
Publishing software
TU Delft policy on research software
- Can it be made open source?
- If yes, TU Delft transfers copyright to you
- If no, contact your data steward
- Apply pre-approved open source license
- Publish the software (e.g. GitHub/Lab + 4TU for DOI)
- Register software with PURE
- If published in 4TU.ResearchData, this is done automatically
Publishing software
Commercial vs. open source
Can co-exist (e.g. RStudio, NextCloud, ownCloud, Linux distros)
- Software is open source, maintenance and support is profitable
- Free for individuals, commercial licenses
- Free basic model, proprietary advanced usage